Data Analytics for Web and Social Media
Week 4: Unsupervised Learning Techniques

Feb-2026
Introduction
- Predictive Analytics:
- All about the dependent variables
- What if there is no dependent variable?
- Sales purchases
- Reviews without a score
- Website paths
- …
- General idea:
- Putting similar items into a group
- Finding features

Clustering Methods: Comparison
When to Use Which Method?
Frequent Itemset
- What items occur together frequently?
- Examples:
- Beer, pizza, diapers (hoax).
- Golden iPhones and shiny cases (or transparent ones?).
- Formally:
- Set of items: \(I = \{beer, pizza, diapers\}\).
- Rule: \(\{beer, pizza\} \rightarrow \{diapers\}\).
- Became famous because of market basket analysis.
- Examples:

Example
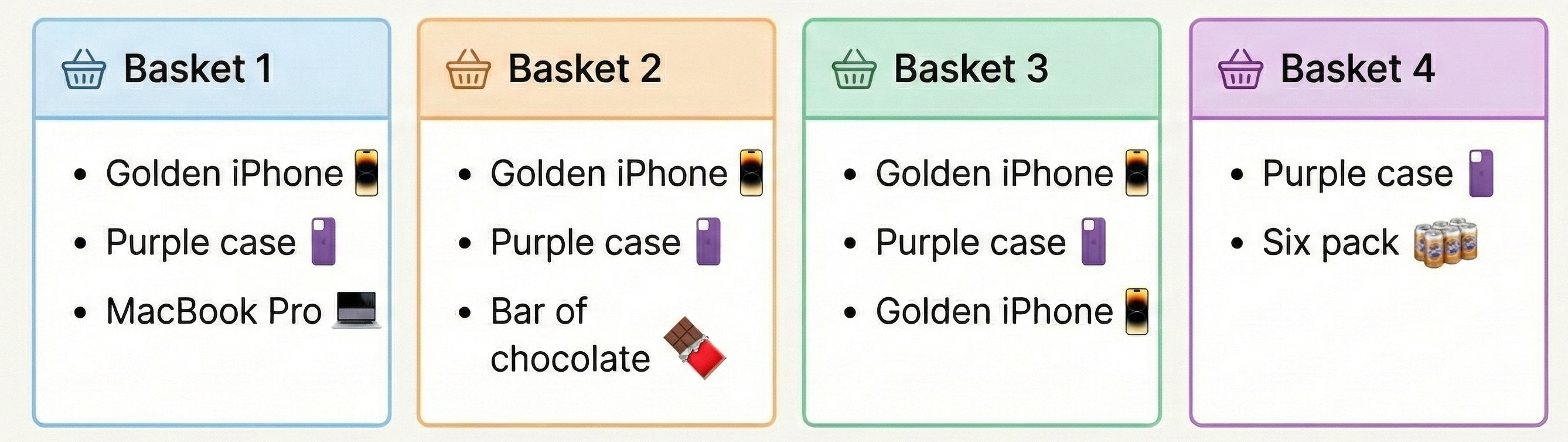
- Example: We have 4 Baskets
![]()
Measuring Impact: Support
Support: The number of times \(A\) appears among the transactions. \[ sup(A) = \frac{|\{A \subseteq t | t \in T\}|}{|T|} \]
Example: Calculate the support of Golden iPhone.
Support: The number of times \(A\) appears among the transactions. \[ sup(A) = \frac{|\{A \subseteq t | t \in T\}|}{|T|} \]
Example: Calculate the support of Golden iPhone.

Measuring Impact: Confidence
Confidence: The number of times both itemsets occur together given the occurrence of \(A\). \[ conf(A \rightarrow B) = \frac{sup(A \cap B)}{sup(A)} \]
Example: Calculate the confidence of Golden iPhone \(\rightarrow\) Purple Case.

Confidence: The number of times both itemsets occur together given the occurrence of \(A\). \[ conf(A \rightarrow B) = \frac{sup(A \cap B)}{sup(A)} \]
Example: Calculate the confidence of Golden iPhone \(\rightarrow\) Purple Case.

Measuring Impact: Lift
Lift: The support for both itemsets occurring together given they are independent. \[ lift(A \rightarrow B) = \frac{sup(A \cap B)}{sup(A) \times sup(B)} \]
Example: Calculate the lift of Golden iPhone \(\rightarrow\) Purple Case.

Lift: The support for both itemsets occurring together given they are independent. \[ lift(A \rightarrow B) = \frac{sup(A \cap B)}{sup(A) \times sup(B)} \]
Example: Calculate the lift of Golden iPhone \(\rightarrow\) Purple Case.

Lift value: example 1
\[ lift(A \rightarrow B) = \frac{sup(A \cap B)}{sup(A) \times sup(B)} \]
- Interpretation:
- If lift > 1: Indicates both items are dependent on each other.
- If lift = 1: Indicates both items are independent.
- If lift < 1: Items are substitutes for each other.

Lift value: example 2
\[ lift(A \rightarrow B) = \frac{sup(A \cap B)}{sup(A) \times sup(B)} \]
- Interpretation:
- If lift > 1: Indicates both items are dependent on each other.
- If lift = 1: Indicates both items are independent.
- If lift < 1: Items are substitutes for each other.

A-Priori Algorithm
A-Priori Algorithm: Example
- A-Priori Algorithm Example (minSup 50%):
![]()

A-Priori Algorithm: Exercise
- Use the A-Priori Algorithm to find the frequent itemsets in the given transaction list.
- Minimum Support (minSup) = 60%.

A-Priori Algorithm: Solution
- Minimum Support (minSup) = 60%.

Example
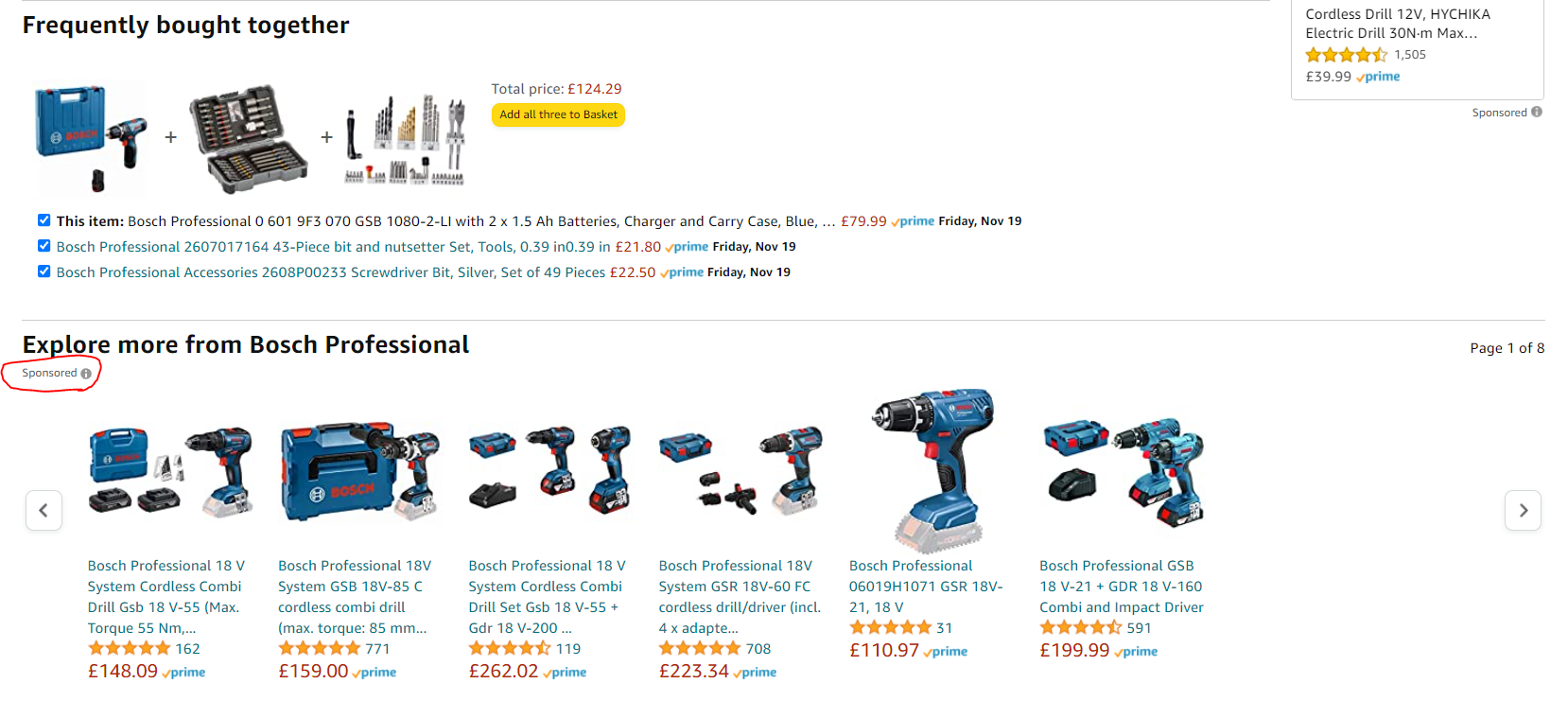
Basics
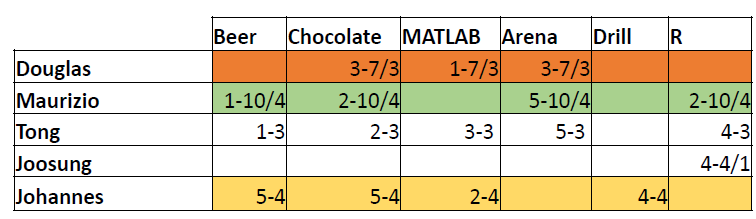
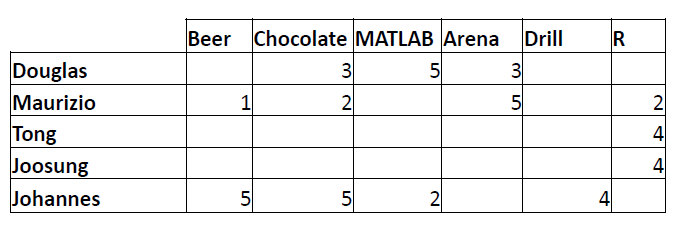
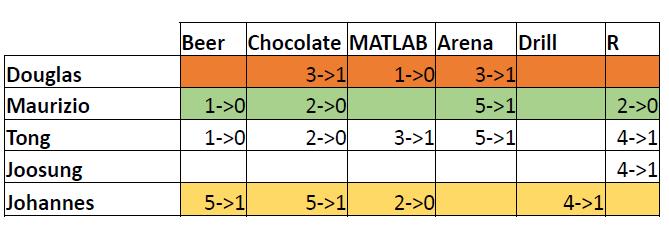
Representation: Utility Matrix
- Utility Matrix: Describes the relationship between users and items.
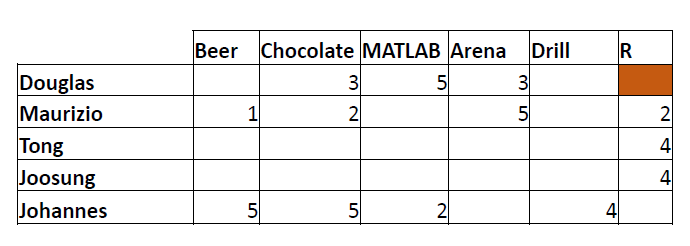
Question: Does Douglas like R?
Collaborative Filtering
- Collaborative Filtering:
- Connecting users through similarity in items: User-to-user.
- Connecting items through similarity in users: - Item-to-item.
Similarity Measures: Example
Similarity Measures: Exercise
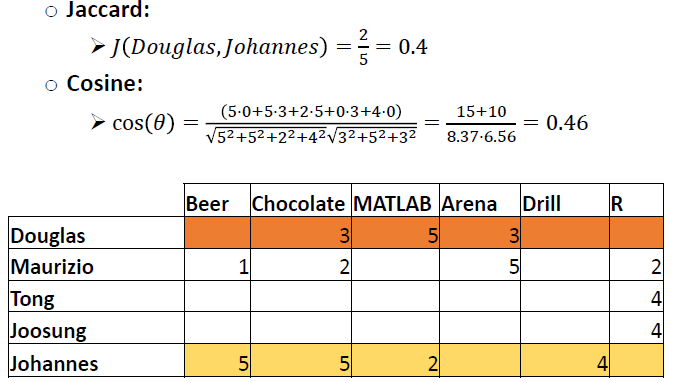
Question:
- Find the similarity between Douglas and Maurizio.
- Find the similarity between Johannes and Maurizio.
- What product(s) would you recommend for Maurizio?
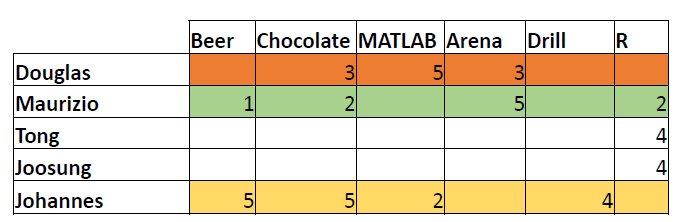
Similarity Measures: Q1 Solution
Q1: Find similarity between Douglas and Maurizio.

Similarity Measures: Q2 Solution
Q2: Find similarity between Johannes and Maurizio.

Similarity Measures: Q3 Solution
Question 3: What product(s) would you recommend for Maurizio?
- Recommendation Based on Similarity:
- Highest similarity with Douglas.
- Not previously acquired products that Douglas likes: MATLAB.
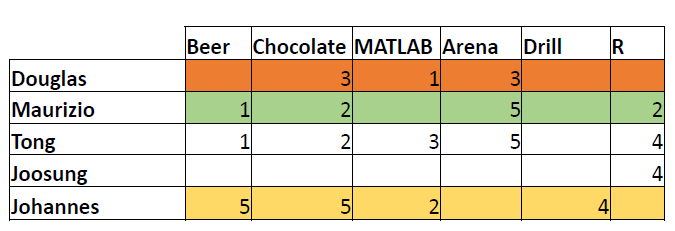
Similarity Measures: Q3+
Question 3+: What product(s) would you recommend for Maurizio now?
- Highest similarity with Douglas and Tong.
- Average rank of MATLAB:
- For Douglas: Last 1 over 3 items; For Tong: Top 3 over 5 items.
- Average ranking: Less than the middle.
- Conclusion: No recommendation.
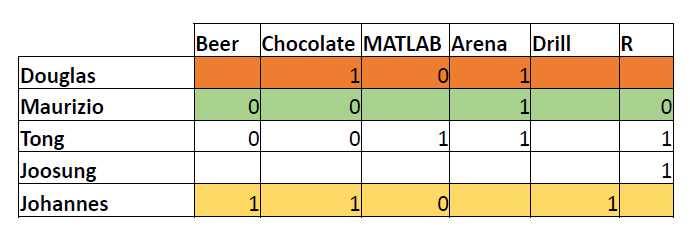
Other Actions: Cut-off
Other actions to improve results:
- Rounding, for example, cut-off at 3.
Other Actions: Cut-off (cont.)
Other actions to improve results:
- Rounding, for example, cut-off at 3.
Other Actions: Normalisation
Other actions to improve results:
- Subtract average of users’ rating from all ratings
- Turn low ranks into negative numbers and vice versa
- Bigger difference in similarity scores