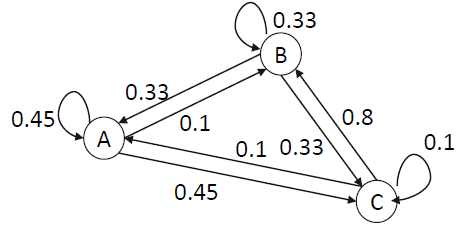
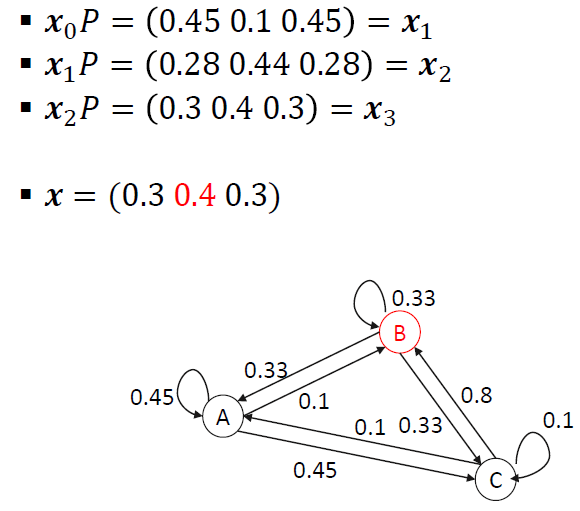
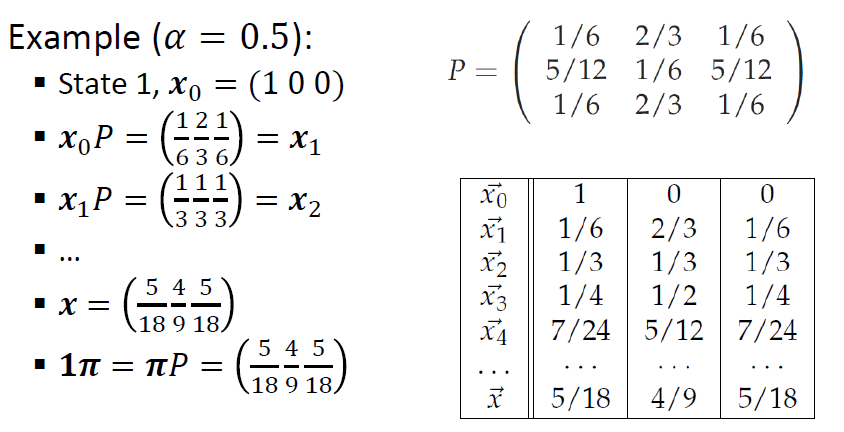import matplotlib.pyplot as plt
# UK data (Dec 2025)
uk_data = {
'Google': 93.35,
'Bing': 4.00,
'Yahoo': 1.10,
'DuckDuckGo': 0.69,
'Other': 0.86
}
uk_sorted = dict(sorted(uk_data.items(), key=lambda item: item[1], reverse=True))
# Worldwide data (2025)
world_data = {
'Google': 89.54,
'Bing': 3.94,
'Yandex': 2.45,
'Yahoo': 1.31,
'DuckDuckGo': 0.72,
'Baidu': 0.64,
'Other': 1.40
}
world_sorted = dict(sorted(world_data.items(), key=lambda item: item[1], reverse=True))
# Plot setup
fig, axes = plt.subplots(1, 2)
# UK bar chart
uk_bars = axes[0].bar(uk_sorted.keys(), uk_sorted.values(), color='#1f77b4')
axes[0].set_title("UK - Dec 2025")
axes[0].set_ylabel("Market Share (%)")
axes[0].tick_params(axis='x', rotation=45)
for bar in uk_bars:
height = bar.get_height()
axes[0].text(bar.get_x() + bar.get_width()/2, height + 1, f'{height:.1f}%',
ha='center', va='bottom', fontsize=9)
# Worldwide bar chart
world_bars = axes[1].bar(world_sorted.keys(), world_sorted.values(), color='#2ca02c')
axes[1].set_title("Worldwide - Dec 2025")
axes[1].tick_params(axis='x', rotation=45)
for bar in world_bars:
height = bar.get_height()
axes[1].text(bar.get_x() + bar.get_width()/2, height + 1, f'{height:.1f}%',
ha='center', va='bottom', fontsize=9)
plt.tight_layout()
plt.show()